Introduction
After architecting disaster recovery solutions for VMware Horizon deployments across dozens of organizations, I’ve learned that successful DR planning requires more than just technical implementation—it demands a comprehensive understanding of business requirements, recovery objectives, and the unique challenges of virtual desktop infrastructure in cloud environments.
In this comprehensive use case, I’ll walk you through architecting a robust disaster recovery plan for VMware Horizon on VMware Cloud on AWS. This isn’t theoretical guidance—it’s based on real-world implementations I’ve designed and deployed for organizations ranging from regional businesses to global enterprises with thousands of virtual desktops.
The combination of VMware Horizon and VMware Cloud on AWS provides unprecedented opportunities for disaster recovery, but it also introduces complexity that requires careful planning and execution. You’ll learn not just what to implement, but why each decision matters and how to avoid the common pitfalls I’ve encountered in production deployments.
Understanding Horizon DR Requirements
Business Continuity Fundamentals
Before diving into technical architecture, you must understand your organization’s business continuity requirements. In my experience, many Horizon DR projects fail because they focus on technical capabilities without aligning to business needs.
Recovery Time Objective (RTO): This defines how quickly your virtual desktop environment must be operational after a disaster. For Horizon deployments, I typically see RTOs ranging from 4 hours for non-critical environments to 30 minutes for mission-critical operations.
Recovery Point Objective (RPO): This determines how much data loss is acceptable. For virtual desktops with persistent data, RPOs often range from 15 minutes to 4 hours, depending on the criticality of user data and applications.
User Experience Requirements: Consider the acceptable degradation in user experience during DR scenarios. This includes reduced desktop performance, limited application availability, and potential workflow changes.
Horizon-Specific DR Challenges
Virtual desktop infrastructure presents unique disaster recovery challenges that don’t exist in traditional server environments:
User State Persistence: Unlike stateless applications, virtual desktops contain user-specific data, settings, and application states that must be preserved and recovered.
Scale Considerations: Horizon environments often support hundreds or thousands of concurrent users. DR solutions must handle this scale while maintaining acceptable performance.
Application Dependencies: Virtual desktops depend on numerous infrastructure components including Active Directory, file servers, application servers, and network services.
Licensing Complexity: DR scenarios must account for Microsoft Windows licensing, application licensing, and VMware licensing across primary and secondary sites.
VMware Cloud on AWS Architecture Overview
Understanding the Platform
VMware Cloud on AWS provides a unique platform for Horizon disaster recovery by offering native VMware infrastructure in AWS data centers. Based on my experience with multiple VMware Cloud deployments, this platform offers several advantages for DR scenarios:
Native VMware Integration: VMware Cloud on AWS runs the same vSphere, vSAN, and NSX technologies as your on-premises environment, simplifying replication and failover procedures.
Elastic Scaling: The platform allows rapid scaling of compute and storage resources, essential for accommodating disaster recovery workloads.
AWS Service Integration: Access to native AWS services like S3, Route 53, and Direct Connect enhances DR capabilities and provides additional recovery options.
Network Architecture Considerations
Network design is critical for successful Horizon DR on VMware Cloud on AWS. Navigate to the VMware Cloud console at vmc.vmware.com to begin planning your network architecture.
Connectivity Options: In the VMware Cloud console, under Networking & Security → VPN, you’ll find multiple connectivity options:
- Route-Based VPN: Suitable for smaller deployments with moderate bandwidth requirements
- Policy-Based VPN: Provides more granular control over traffic routing
- AWS Direct Connect: Essential for large-scale deployments requiring consistent, high-bandwidth connectivity
Segment Configuration: Under Networking & Security → Segments, create network segments that mirror your on-premises Horizon infrastructure:
- Management segment for vCenter, Connection Servers, and infrastructure components
- Desktop segment for virtual desktop workloads
- Application segment for published applications and RDS hosts
- User access segment for external connectivity and load balancing
Disaster Recovery Architecture Design
Multi-Site Architecture Patterns
Based on my experience designing Horizon DR solutions, I recommend one of three architectural patterns depending on your requirements and budget:
Active-Passive Configuration: This is the most common pattern I implement for cost-conscious organizations. The primary site handles all production workloads, while the VMware Cloud on AWS environment remains in standby mode.
Active-Active Configuration: For organizations requiring minimal downtime, this pattern distributes workloads across both sites. Users can access desktops from either location, providing both load distribution and disaster recovery capabilities.
Pilot Light Configuration: A middle-ground approach where core infrastructure components run continuously in VMware Cloud on AWS, but desktop workloads remain dormant until needed.
Component-Level Architecture
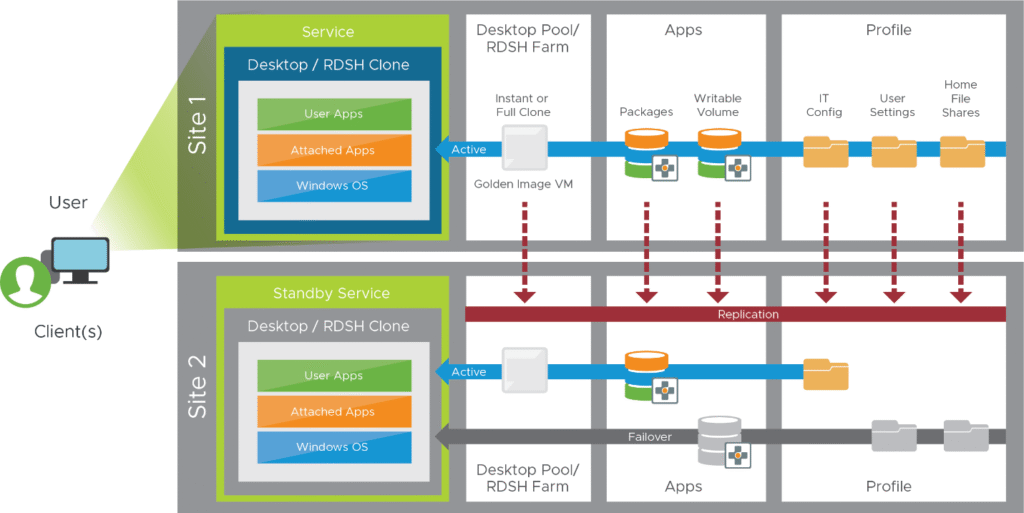
Let me walk you through the specific components and their placement in a typical Horizon DR architecture:
Connection Server Architecture: In the vSphere Client connected to your VMware Cloud environment, navigate to Hosts and Clusters to plan your Connection Server placement:
- Deploy at least two Connection Servers in the DR site for redundancy
- Configure Connection Server replicas to synchronize with the primary site
- Implement load balancing using VMware Cloud on AWS load balancer services
Composer and Instant Clone Architecture: Under VMs and Templates in the vSphere Client, plan your master image and replica placement:
- Replicate master images to VMware Cloud on AWS using vSphere Replication
- Configure Instant Clone parent VMs in the DR site
- Plan for rapid desktop provisioning during failover scenarios
Data Protection and Replication Strategy
vSphere Replication Configuration
vSphere Replication provides the foundation for protecting your Horizon infrastructure. In the vSphere Client, navigate to Configure → vSphere Replication to begin configuration.
Replication Planning: Based on my experience, prioritize replication for these components:
- High Priority (RPO 15-30 minutes): Connection Servers, Composer servers, master images
- Medium Priority (RPO 1-4 hours): Infrastructure VMs, management components
- Low Priority (RPO 4-24 hours): Non-critical supporting systems
Replication Configuration Process:
- Right-click on the VM you want to protect
- Select All vSphere Replication Actions → Configure Replication
- Choose your VMware Cloud on AWS environment as the target site
- Configure RPO settings based on business requirements
- Select appropriate storage policy for replicated data
- Enable guest OS quiescing for application-consistent snapshots
User Data Protection Strategy
Protecting user data requires a multi-layered approach that goes beyond VM replication:
Profile Management: Configure VMware Dynamic Environment Manager (DEM) or Microsoft User Profile Disks to centralize user profile data. In the Horizon Administrator console, navigate to Policies → Profile Management:
- Configure profile repositories on replicated file servers
- Implement profile streaming to reduce logon times
- Configure profile backup and versioning
- Test profile restoration procedures regularly
Home Directory Replication: For organizations using traditional home directories, implement file-level replication:
- Use DFS Replication for Windows-based file servers
- Configure appropriate replication schedules based on change rates
- Monitor replication health and resolve conflicts promptly
- Test file restoration procedures regularly
Site Recovery Manager Integration
SRM Configuration and Setup
VMware Site Recovery Manager provides orchestrated disaster recovery for your Horizon environment. In the vSphere Client, navigate to Site Recovery to begin SRM configuration.
Site Pairing Configuration:
- Navigate to Site Recovery → Open Site Recovery
- Click New Site Pair to connect your on-premises and VMware Cloud environments
- Configure authentication between sites using appropriate credentials
- Verify connectivity and certificate exchange
Array Manager Configuration: Under Array Managers, configure storage replication:
- Add your storage array managers for both sites
- Configure replication relationships between storage systems
- Verify storage mapping and LUN relationships
- Test storage failover procedures
Protection Group Creation
Protection groups define which VMs are protected together and their recovery dependencies. Navigate to Protection Groups in the Site Recovery interface:
Horizon Infrastructure Protection Group:
- Click New Protection Group
- Select vSphere Replication as the replication type
- Add Connection Servers, Composer servers, and infrastructure VMs
- Configure VM dependencies and startup order
- Define network mappings for the recovery site
Desktop Pool Protection Groups: Create separate protection groups for different desktop pools:
- Group VMs by similar recovery requirements and dependencies
- Configure appropriate recovery priorities
- Define custom recovery scripts for application-specific requirements
Recovery Plan Development
Recovery Plan Architecture
Recovery plans orchestrate the failover process and ensure proper startup sequencing. In Site Recovery Manager, navigate to Recovery Plans to create comprehensive recovery procedures.
Recovery Plan Structure: Based on my experience, structure recovery plans in this order:
- Priority 1: Infrastructure services (DNS, DHCP, Active Directory)
- Priority 2: Horizon infrastructure (Connection Servers, Composer)
- Priority 3: Supporting services (file servers, application servers)
- Priority 4: Desktop pools and published applications
Recovery Plan Configuration:
- Click New Recovery Plan
- Select the protection groups to include
- Configure VM startup order and dependencies
- Add custom recovery steps and scripts
- Define network reconfiguration procedures
- Configure post-recovery validation steps
Custom Recovery Scripts
Horizon environments often require custom scripts to handle application-specific recovery tasks. Create these scripts to handle common recovery scenarios:
Connection Server Recovery Script: This script handles Connection Server-specific recovery tasks:
- Verify Connection Server service status
- Update load balancer configurations
- Validate desktop pool configurations
- Test user authentication and desktop assignment
Desktop Pool Validation Script: Automate desktop pool validation after recovery:
- Verify master image availability and configuration
- Validate Instant Clone parent VM status
- Test desktop provisioning and user assignment
- Verify application publishing and entitlements
Network Configuration and Load Balancing
Load Balancer Configuration
Proper load balancing is essential for user access during disaster recovery scenarios. In the VMware Cloud console, navigate to Networking & Security → Load Balancing.
Connection Server Load Balancing:
- Click Add Load Balancer
- Configure a new load balancer for Connection Server access
- Add Connection Servers as pool members
- Configure health checks to monitor Connection Server availability
- Set up SSL termination and certificate management
Health Check Configuration: Configure comprehensive health checks to ensure proper failover:
- HTTP health checks for Connection Server web services
- TCP health checks for PCoIP and Blast protocols
- Custom health checks for application-specific requirements
DNS and Traffic Management
DNS configuration is critical for seamless user experience during disaster recovery. Configure DNS to support automatic failover:
DNS Failover Configuration: Use AWS Route 53 or your existing DNS infrastructure:
- Configure health checks for your primary Horizon environment
- Create DNS records with automatic failover to VMware Cloud on AWS
- Set appropriate TTL values to minimize failover time
- Test DNS failover procedures regularly
Certificate Management: Plan certificate requirements for the DR environment:
- Use wildcard certificates to simplify management
- Ensure certificates are valid for both primary and DR site FQDNs
- Implement automated certificate renewal procedures
- Test certificate validation during failover scenarios
Storage Architecture and Performance
vSAN Configuration in VMware Cloud
VMware Cloud on AWS uses vSAN for storage, which provides excellent performance and resilience for Horizon workloads. In the vSphere Client, navigate to Configure → vSAN to optimize storage configuration.
Storage Policy Configuration: Create storage policies optimized for different Horizon workload types:
- Navigate to Policies and Profiles → VM Storage Policies
- Create policies for different VM types:
- Infrastructure VMs: High availability with RAID-1 mirroring
- Master Images: High performance with RAID-0 striping
- Desktop VMs: Balanced performance and capacity
- Apply appropriate policies during VM provisioning
Performance Optimization: Configure vSAN for optimal Horizon performance:
- Enable deduplication and compression for capacity optimization
- Configure appropriate cache ratios for read/write performance
- Monitor storage performance and adjust policies as needed
- Plan for growth and scaling requirements
Backup and Archive Strategy
Implement comprehensive backup strategies that complement your disaster recovery solution:
VM-Level Backups: Use Veeam Backup & Replication or similar solutions:
- Configure backup jobs for critical infrastructure VMs
- Implement application-aware backups for database systems
- Store backup data in AWS S3 for long-term retention
- Test restore procedures regularly
Configuration Backups: Backup Horizon configuration data:
- Export Horizon Administrator configuration regularly
- Backup Connection Server databases
- Document custom configurations and integrations
- Store configuration backups in multiple locations
Testing and Validation Procedures
Disaster Recovery Testing Framework
Regular testing is essential for ensuring your DR solution works when needed. Based on my experience, implement a comprehensive testing framework:
Monthly Testing:
- Test individual VM failover using vSphere Replication
- Validate backup and restore procedures
- Test network connectivity and DNS failover
- Verify monitoring and alerting systems
Quarterly Testing:
- Execute complete Site Recovery Manager recovery plans
- Test end-to-end user access and desktop functionality
- Validate application performance and availability
- Conduct failback procedures and data synchronization
Annual Testing:
- Conduct full-scale disaster recovery exercises
- Test extended outage scenarios
- Validate business continuity procedures
- Review and update recovery documentation
Test Automation and Validation
Automate testing procedures to ensure consistency and reduce manual effort:
Automated Test Scripts: Develop scripts to validate recovery procedures:
- Connection Server availability and functionality
- Desktop pool status and provisioning
- User authentication and desktop assignment
- Application publishing and entitlements
Performance Validation: Implement automated performance testing:
- Desktop logon time measurements
- Application launch performance
- Network latency and throughput testing
- Storage performance validation
Monitoring and Alerting
Comprehensive Monitoring Strategy
Implement monitoring that covers both primary and disaster recovery environments. Use VMware vRealize Operations or similar tools to monitor your Horizon infrastructure.
Infrastructure Monitoring: Configure monitoring for critical components:
- Connection Server health and performance
- vCenter and ESXi host status
- Storage performance and capacity
- Network connectivity and latency
Replication Monitoring: Monitor replication health and status:
- vSphere Replication status and RPO compliance
- Site Recovery Manager health checks
- Storage replication status and lag
- Network connectivity between sites
Alerting and Escalation
Configure comprehensive alerting to ensure rapid response to issues:
Critical Alerts: Configure immediate notification for:
- Primary site outages or connectivity loss
- Replication failures or RPO violations
- Connection Server failures or service disruptions
- Storage capacity or performance issues
Escalation Procedures: Define clear escalation paths:
- Level 1: Operations team notification and initial response
- Level 2: Technical team engagement and troubleshooting
- Level 3: Management notification and disaster declaration
- Level 4: Full disaster recovery activation
Security Considerations
Security Architecture in DR Environment
Maintain security standards in your disaster recovery environment that match or exceed your primary site:
Network Security: Configure NSX security policies in VMware Cloud on AWS:
- Navigate to Networking & Security → Security → Distributed Firewall
- Replicate security policies from your primary environment
- Configure micro-segmentation for desktop and application traffic
- Implement intrusion detection and prevention
Access Controls: Implement comprehensive access controls:
- Multi-factor authentication for administrative access
- Role-based access control for recovery operations
- Audit logging for all recovery activities
- Secure communication channels between sites
Compliance and Audit Requirements
Ensure your DR solution meets regulatory and compliance requirements:
Data Protection: Implement appropriate data protection measures:
- Encryption in transit and at rest
- Data residency and sovereignty requirements
- Backup encryption and secure storage
- Secure data destruction procedures
Audit Trail: Maintain comprehensive audit trails:
- Recovery operation logging and documentation
- Access control and authentication logs
- Configuration change tracking
- Regular compliance assessments and reporting
Cost Optimization Strategies
VMware Cloud on AWS Cost Management
Disaster recovery can be expensive if not properly managed. Implement cost optimization strategies:
Right-Sizing Resources: In the VMware Cloud console, monitor resource utilization:
- Use appropriate instance types for different workload requirements
- Implement auto-scaling for variable workloads
- Schedule non-critical resources to reduce costs
- Monitor and optimize storage utilization
Reserved Capacity: Use reserved instances for predictable workloads:
- Analyze usage patterns to identify reservation opportunities
- Purchase reserved capacity for steady-state DR infrastructure
- Use on-demand capacity for burst requirements
- Monitor reservation utilization and adjust as needed
Operational Cost Optimization
Automation: Reduce operational costs through automation:
- Automate routine testing and validation procedures
- Implement self-service recovery capabilities where appropriate
- Use infrastructure as code for consistent deployments
- Automate monitoring and alerting procedures
Resource Sharing: Optimize resource utilization:
- Share DR infrastructure across multiple applications
- Use multi-tenant architectures where appropriate
- Implement resource pooling and dynamic allocation
- Optimize licensing across primary and DR sites
Operational Procedures and Documentation
Standard Operating Procedures
Develop comprehensive operational procedures for disaster recovery scenarios:
Disaster Declaration Procedures:
- Define criteria for disaster declaration
- Establish decision-making authority and escalation paths
- Create communication templates and contact lists
- Document approval processes and sign-offs
Recovery Execution Procedures:
- Step-by-step recovery plan execution
- Validation and testing procedures
- User communication and support procedures
- Monitoring and troubleshooting guidelines
Documentation and Knowledge Management
Maintain comprehensive documentation for your DR solution:
Technical Documentation:
- Architecture diagrams and component relationships
- Configuration details and dependencies
- Network diagrams and connectivity requirements
- Troubleshooting guides and known issues
Operational Documentation:
- Recovery procedures and checklists
- Contact information and escalation procedures
- Communication templates and user guides
- Training materials and certification requirements
Continuous Improvement and Optimization
Performance Monitoring and Analysis
Continuously monitor and optimize your DR solution:
Performance Metrics: Track key performance indicators:
- Recovery time objectives and actual recovery times
- Recovery point objectives and data loss measurements
- User experience metrics during DR scenarios
- Infrastructure performance and capacity utilization
Regular Reviews: Conduct regular solution reviews:
- Monthly operational reviews and metrics analysis
- Quarterly architecture reviews and optimization
- Annual strategic reviews and planning
- Post-incident reviews and lessons learned
Technology Evolution and Updates
Stay current with technology improvements and best practices:
Technology Updates:
- Monitor VMware product roadmaps and new features
- Evaluate new AWS services and capabilities
- Assess third-party tools and integrations
- Plan for technology refresh and migration
Best Practice Evolution:
- Participate in industry forums and user groups
- Attend conferences and training sessions
- Engage with vendors and technology partners
- Share experiences and learn from peers
Conclusion
Architecting a comprehensive disaster recovery solution for VMware Horizon on VMware Cloud on AWS requires careful planning, systematic implementation, and ongoing optimization. The combination of these technologies provides powerful capabilities for protecting virtual desktop infrastructure, but success depends on understanding both the technical requirements and business objectives.
Based on my experience with dozens of similar implementations, the key to success lies in thorough planning, comprehensive testing, and commitment to ongoing improvement. Organizations that invest in proper architecture design, operational procedures, and regular testing typically achieve their recovery objectives and maintain user productivity during disaster scenarios.
The integration between VMware Horizon and VMware Cloud on AWS continues to evolve, providing new capabilities and optimization opportunities. Staying current with these developments and continuously refining your DR strategy ensures your organization remains prepared for any disaster scenario while optimizing costs and maintaining security standards.
Remember that disaster recovery is not a one-time project but an ongoing operational capability. Regular testing, documentation updates, and technology refresh ensure your DR solution continues to meet business requirements as your organization grows and evolves. The investment in comprehensive disaster recovery planning pays dividends in business continuity, regulatory compliance, and peace of mind.